Automatic speech recognition (ASR)
Voice AI training data for recognition workflows and real-world speech model training.

Solutions
Voice AI systems depend on more than clean audio. They depend on high-quality speech data that reflects how people actually speak - across accents, dialects, environments, interruptions, and real-world conversations. IndiVillage Tech provides voice AI data services for teams building ASR, TTS, conversational AI, speech analytics, and multilingual voice systems through structured collection, transcription, annotation, and QA-led delivery.

Secure onboarding. Human-in-the-loop QA. Tool-agnostic delivery.
Real-world speech is rarely clean or predictable. People switch languages mid-sentence, overlap in conversation, pause unexpectedly, change tone, speak through noise, and use words differently across regions and contexts.
That is why voice AI data services need to go beyond basic transcription. Training reliable voice models requires structured speech data collection, accurate audio annotation, speaker-aware workflows, and quality frameworks that preserve meaning, intent, and acoustic context at scale.

Voice AI training data for recognition workflows and real-world speech model training.

Reviewed speech data that supports natural-sounding synthesis and pronunciation quality.

Dialogue and voice assistant data prepared for real interaction patterns.

Speech data workflows for analytics systems, intent detection, and call intelligence.

Data preparation for contact center automation and intelligence workflows.

Speech data collection and annotation across languages, accents, and regional markets.

Support for voice models where dialect and regional coverage are hard to source.

Speaker-aware transcription, diarization support, and multi-speaker review workflows.

Intent, emotion, sentiment, and conversational signal annotation for voice AI.

Acoustic event labeling and audio classification for real-world speech systems.

High-performing voice models start with the right speech data collection strategy. IndiVillage helps teams build structured audio datasets across languages, accents, environments, and speaker profiles so the resulting data is usable for model training, evaluation, and iteration.
We support scripted and unscripted speech collection, prompt-based recordings, multilingual voice data, dialect coverage, domain-specific audio capture, and environment-specific collection designed around the needs of ASR, TTS, and conversational AI systems.
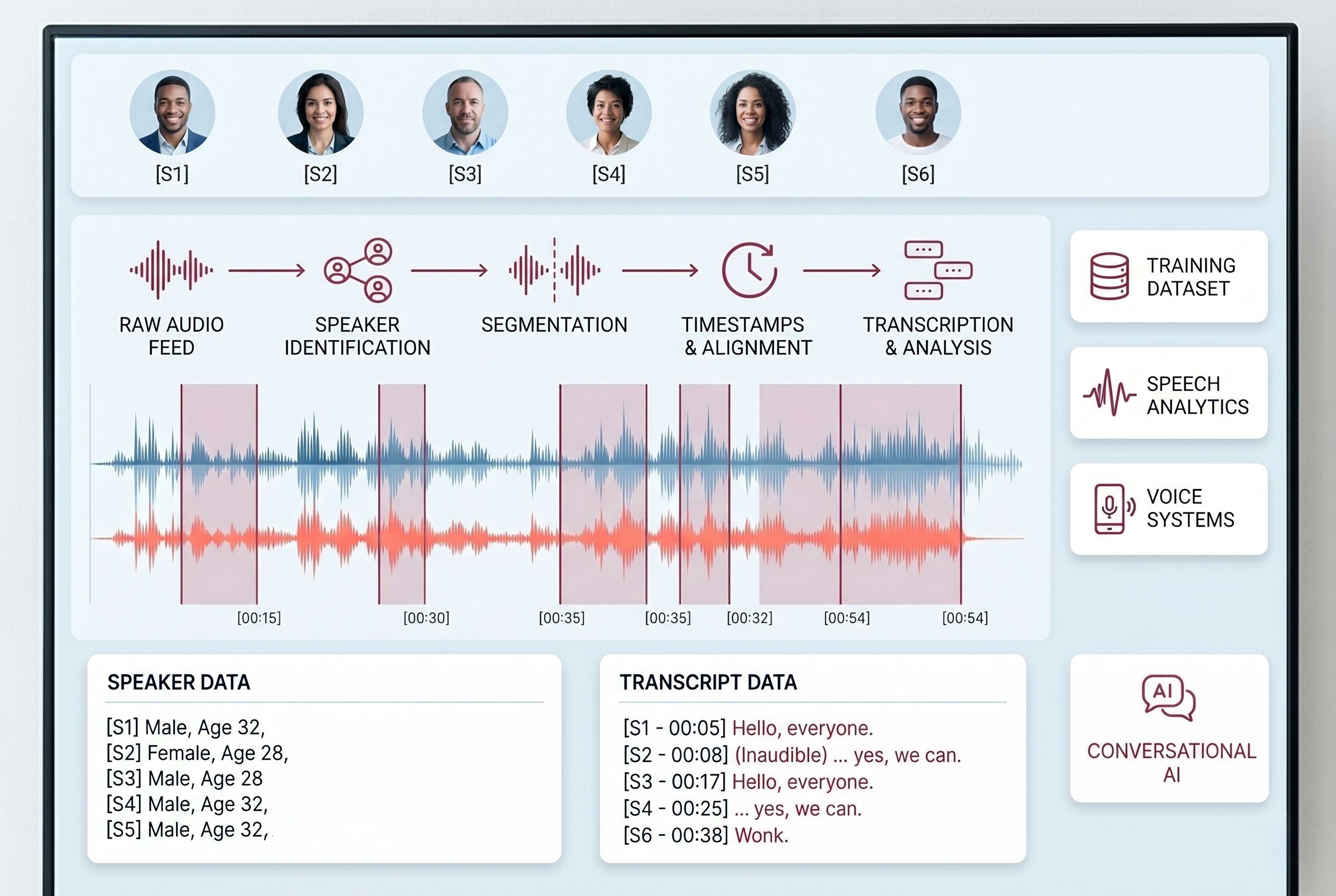
Speech transcription for AI requires more than word accuracy. It requires consistency in segmentation, timestamping, speaker handling, and the treatment of hesitations, overlaps, and real conversational flow.
IndiVillage provides audio transcription services for voice AI teams working on ASR training data, speech analytics, and conversational systems. This includes verbatim transcription, clean-read transcription, utterance segmentation, timestamp alignment, and structured workflows for multi-speaker audio.

Voice AI models often need more than text output. They need annotated signals that help systems understand intent, tone, speaker turns, emotional cues, acoustic events, and conversational structure.
Our audio annotation services support intent labeling, emotion tagging, sentiment annotation, keyword and wake-word labeling, accent and dialect tagging, code-switching annotation, pause and hesitation tagging, and other layers of labeling that improve how voice systems perform in the real world.
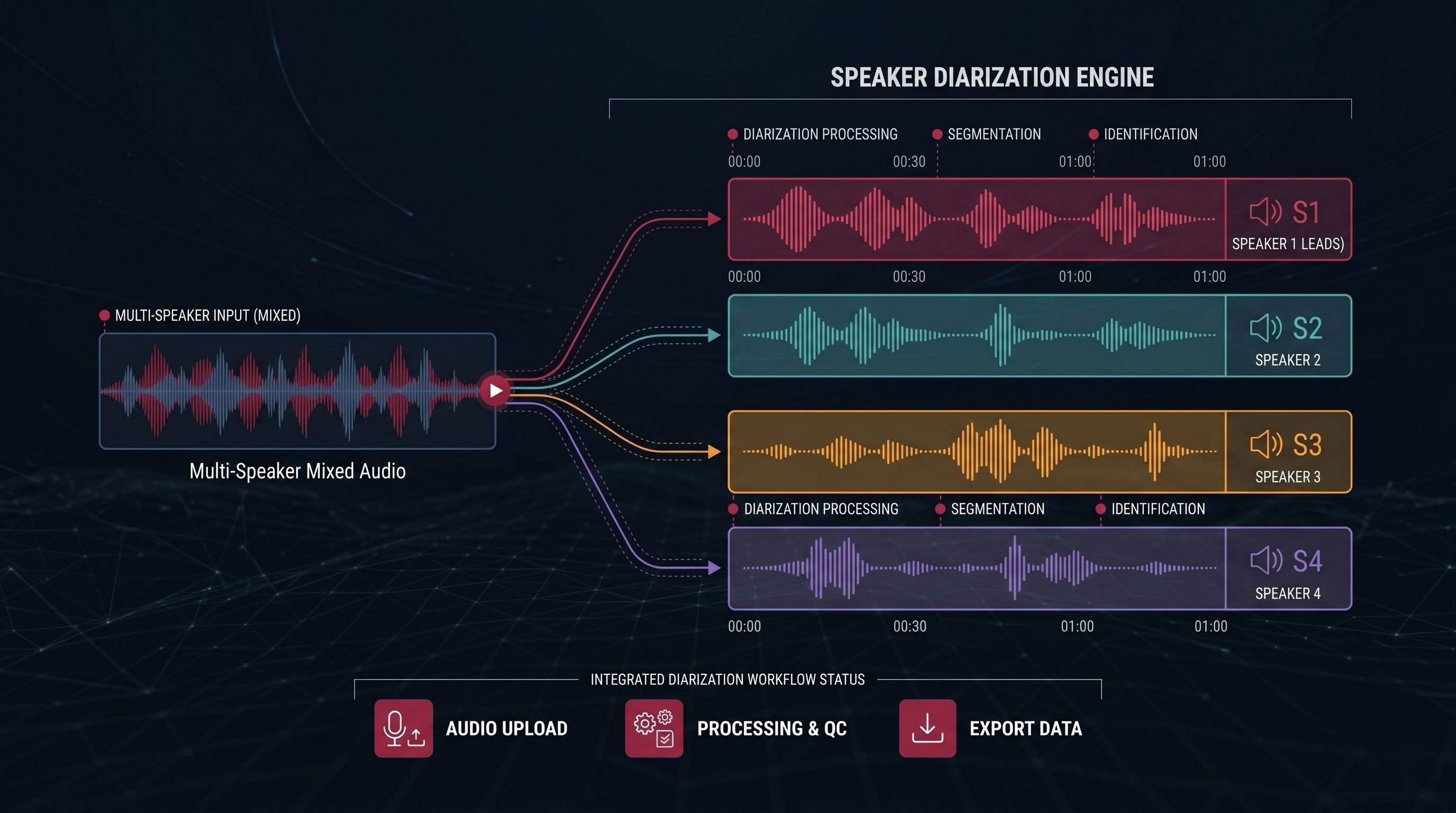
When multiple speakers appear in the same recording, transcription quality alone is not enough. Voice AI systems need clear speaker boundaries and structured diarization support to understand who said what, when, and in what conversational sequence.
IndiVillage supports multi-speaker audio workflows through speaker-aware transcription, diarization-aligned review, overlapping speech handling, and QA processes designed for complex conversational audio.

Conversational AI systems need data that reflects real interaction, not just isolated utterances. That includes turn-taking, interruptions, pauses, incomplete thoughts, repeated phrases, and the ways people naturally speak in support, assistant, and enterprise voice settings.
We help prepare conversational AI training data through dialogue segmentation, turn-level annotation, interruption tagging, intent labeling, response review, and failure-mode annotation for systems that need to perform in live human conversations.

Text-to-speech systems depend on carefully reviewed data that captures pronunciation, pacing, emphasis, and natural variation in speech. Poorly structured TTS data can make voice output sound flat, inconsistent, or unnatural.
IndiVillage supports TTS data preparation through utterance review, pronunciation QA, prosody annotation, emotion and style tagging, and quality review workflows built for natural-sounding speech generation.

Many voice AI products fail when they move beyond idealized English-only datasets. Regional accents, dialect variation, code-switching, and low-resource language behavior all create challenges that generic speech pipelines often miss.
IndiVillage supports multilingual speech data collection and annotation for teams building voice systems across languages, accents, and regional markets. Our workflows are designed to improve data consistency while preserving the real variation that voice systems need to learn from.

Voice AI data operations need structure from the beginning. At IndiVillage, quality is built into the workflow through guideline design, workforce calibration, multi-layer review, and feedback loops that reduce inconsistency over time.
Our teams work within client tools or aligned delivery environments depending on workflow, security, and output requirements. Whether the need is speech data collection, audio transcription, multilingual annotation, or conversational AI data preparation, the focus stays the same: consistent delivery, usable outputs, and quality that holds up at scale.
Voice AI data operations for product teams, enterprise teams, and domain-specific speech systems.

Speech data support for voice assistant products and real-time interaction systems.

Dialogue and annotation workflows for enterprise conversational AI.

Speech data for contact center automation, analytics, and intelligence systems.

Structured speech data for analytics platforms and model evaluation.
Multilingual voice data for region-aware product experiences.

Voice data support for in-vehicle assistants and speech interfaces.

Reviewed speech data for text-to-speech applications.

Voice datasets for domain-specific speech model development.

Audio data and labeling workflows for audio intelligence platforms.
If your model needs stronger speech data, cleaner annotation workflows, or more structured QA, IndiVillage can help design a delivery model around your languages, use case, and production goals.
Quick answers to help you make smarter, faster decisions with confidence
Voice AI data services include speech data collection, audio transcription, annotation, speaker-aware labeling, and quality review used to train and improve ASR, TTS, conversational AI, and speech analytics systems.
IndiVillage supports scripted and unscripted speech, conversational audio, multilingual datasets, multi-speaker recordings, regional accent coverage, domain-specific voice data, and environment-specific audio collection.
Yes. IndiVillage supports ASR training data through transcription, timestamping, segmentation, speaker-aware review, code-switching annotation, and quality control processes designed for real-world speech.
Yes. We support TTS data preparation through utterance review, pronunciation QA, prosody tagging, emotion annotation, and other workflows that improve the naturalness and usability of synthesized speech.
Yes. IndiVillage supports multilingual speech data collection and annotation across languages, accents, dialects, and region-specific voice workflows depending on project requirements.
Yes. We support multi-speaker audio workflows through structured transcription, speaker diarization support, overlapping speech review, and speaker-aware QA.
Many voice AI systems also require intent labeling, emotion tagging, sentiment annotation, pause and hesitation labeling, accent tagging, wake-word labeling, and conversational turn annotation.
Quality is managed through collection design, annotation guidelines, workforce calibration, peer review, QA audits, escalation logic, and feedback loops that reduce drift and improve consistency over time.
Yes. IndiVillage follows a tool-agnostic delivery model and can work within client-managed tools or aligned workflow environments based on security and delivery requirements.
Yes. Many voice AI projects begin with a pilot to align on schema, workflow, quality criteria, and output format before scaling into larger production programs.
Tell us about your AI data requirements and our team will help map the right workflow.